The GitHub repository for the project code can be found here.
1. Abstract
A series of prior results, including those by Gichoya et al. (2022), have shown that it is possible to use deep convolutional neural networks to predict a patient’s self-reported race from chest radiographs with high accuracies. Since this result displays significant ethical concerns for medical imaging algorithms, we aim to reproduce these results and investigate the implications this algorithm could have for race-based medicine and the racial inequalities reinforced by algorithms. We use a subset of the chest radiographs obtained from the ChexPert dataset, aiming to classify images into Black, White, Asian. We primarily train and test on a subset of data with equal proportions amongst all races. In particular, we compare the results of pretrained and untrained ResNet18 models and the EfficientNetB0 model. Our results achieve around 70 % accuracy, displaying some racial bias and having minimal gender bias. We therefore conclude that, on a smaller scale, we have confirmed that it is indeed possible to train neural networks to accurately classify race from chest radiographs.
2. Introduction
Deep neural networks are increasingly getting popular in medicine as diagnostic tools. While at times suprassing the accuracy of experts, results such as those by Seyyed-Kalantari et al. (2021) show concerning results of underdiagnosis for patients that are Black, Hispanic, younger, or belonging to a lower socieconomic status groups. Problematically this reinforces a history of minority groups or economically vulnerable groups receiving inadequate medical care, especially when many publicly available datasets are disproportionately represent White patients.
As Seyyed-Kalantari et al. (2021) suggest, this may be a matter of confounding variables as bias amplification or differing prevalence. However, a paper by Gichoya et al. (2022) investigated the direct question - can race be inferred from chest X-rays? Clincially speaking this is something that is not expected, it is an implicit assumption that chest radiographs contain no information about one’s demographic characteristics, beyond those most relevant to physiology, such as age or biological sex. Many models specifically exclude characteristics so that classification is based solely on the image. However, deep neural networks are often a black box, being capable on picking up on pixel level patterns that are surprising.
Indeed, the authors Gichoya et al. (2022) found that by using self-reported race labels, those being Black, White, and Asian, it is possible to classify chest radiographs into these three categories with high accuracies (0.91–0.99 using AUC metrics). To the extent that they investigated, this was not based on potentially race related characteristics, including bone or breast density or disease prevalence. Even highly degraded versions of the image maintained a high performance. Moreover, this pattern could not be replicated with algorithms that did not use the image data - “logistic regression model (AUC 0·65), a random forest classifier (0·64), and an XGBoost model (0·64) to classify race on the basis of age, sex, gender, disease, and body habitus performed much worse than the race classifiers trained on imaging data”. So as they conclude, “medical AI systems can easily learn to recognise self-reported racial identity from medical images, and that this capability is extremely difficult to isolate” - the problem may be prevalent in a large range of algorithms and would be difficult to correct for. Moreover, the fact that they obtained the results by training on a variety of popular and publicly available datasets for medical images, including the MIMIC-CXR, CheXpert, National lung cancer screening trial, RSNA Pulmonary Embolism CT, and the Digital Hand Atlas, further suggests that this could largely applicable to other AI projects.
This paper is also not a standalone result. A prior paper by Yi et al. (2021) demonstrated that age and sex can be determined for Chinese and American populations. A paper by Adleberg et al. (2022), training on the MIMIC-CXR dataset, created a deep learning model that can extract self-reported information such as age, gender, race, ethnicity with high accuracies, even insurance status at moderate rates.
While the question of whether their results are reproducible has been more adequately answered elsewhere, we are interested if it possible to reproduce their results on a smaller scale. Moreover, we aim to answer the ethical implications of their work beyond the problems of bias it poses to deep neural networks. Gichoya et al. (2022) “emphasise that the ability of AI to predict racial identity is itself not the issue of importance”, but is this enough? It does not seem to be adequate to stop at this conclusion when racial classification itself is a goal that is long rooted in the painful histories of eugenics, slavery, and colonization. To this extent we will exposit some more about the definition of race and its use in medicine.
Race in Medicine
The most concerning question we face are the implications of this model. The direct usages for this algorithm are limited. However, its main value is in its demonstration; anyone using an AI algorithm may be unknowingly be using similar procedures to this one to classify self-reported and use this as a proxy for other classifcation tasks.
We cannot ignore that there still may be potential users of this algorithm. The very goal of racial classification contains an implicit assumption that race exists. However, we must address two central questions: what race represents in medicine, and how race has been used for clinical practice.
Does Race Exist?
Whether race exists as a biological phenomenon, and not as a social construct, is a hotly debated issue. As Cerdeña, Plaisime, and Tsai (2020) note, “race was developed as a tool to divide and control populations worldwide. Race is thus a social and power construct with meanings that have shifted over time to suit political goals, including to assert biological inferiority of dark-skinned populations.”
One justification for the biological reality of races is based on the assumption that different races have distinct genetics from one another, and can be fit into genetic groups. However, Maglo, Mersha, and Martin (2016) note that humans are not distinct by evolutionary criteria and genetic similarities between “human races, understood as continental clusters, have no taxonomic meaning”, with there being “tremendous diversity within groups” [2]. Whether race defines a genetic profile is therefore unclear at best, with correlations between race and disease being confounded by variables such as the association between race and socioeconomic variables.
What is Race-based Medicine?
It is possible that some may be interested in using this algorithm to deduce the race of an individual and use this as part of medical decisions. There are some correlations between disease prevalence and race. Maglo, Mersha, and Martin (2016) note that “Recent studies showed that ancestry mapping has been successfully applied for disease in which prevalence is significantly different between the ancestral populations to identify genomic regions harboring diseases susceptibility loci for cardiovascular disease (Tang et al. (2005)), multiple sclerosis (Reich et al. (2005)), prostate cancer (Freedman et al. (2006)), obesity (Cheng et al. (2009)), and asthma (Vergara et al. (2009))” [2].
These practices would be characteristic of race-based medicine. As Cerdeña, Plaisime, and Tsai (2020) argue, this is “the system by which research characterizing race as an essential, biological variable, [which] translates into clinical practice, leading to inequitable care” [1]. Notably, then, race-based medicine has come under heavy criticism.
The Harms of Race-based Medicine
As stated above, race is not an accurate proxy for genetics. Cerdeña, Plaisime, and Tsai (2020) note that in medical practices, race is used as an inaccurate guideline for medical care: “Black patients are presumed to have greater muscle mass …On the basis of the understanding that Asian patients have higher visceral body fat than do people of other races, they are considered to be at risk for diabetes at lower body-mass indices” [1]. As they note, race-based medicine can be founded more on racial stereotypes and generalizations rather than.
Moreover, race-based medicine can lead to ineffective treatements. Apeles (2022) summarizes the results of a study on race-based prescriptions for Black patients for high blood pressure. While this study demonstrates that alternative prescriptions for Black patients with high blood pressure have been shown to be ineffective, “Practice guidelines have long recommended that Black patients with high blood pressure and no comorbidities be treated initially with a thiazide diuretic or a calcium channel blocker (CCB) instead of an angiotensin converting enzyme inhibitor (ACEI) and/or angiotensin receptor blocker (ARB). By contrast, non-Black patients can be prescribed any of those medicines regardless of comorbidities.” In addition, the authors of the study found that “other factors may be more important than considerations of race, such as dose, the addition of second or third drugs, medication adherence, and dietary and lifestyle interventions. Follow-up care was important, and the Black patients who had more frequent clinical encounters tended to have better control of their blood pressure.”
In addition, Vyas, Eisenstein, and Jones (2020) argue that race is ill-suited as a correction factor for medical algorithms. As they found, algorithms as the American Heart Association (AHA) Get with the Guidelines–Heart Failure Risk Score, which predicts the likelihood of death from heart failure, the Vaginal Birth after Cesarean (VBAC), which predicts the risk of labor for someone with a previous cesarean section, and STONE score, which predicts the likelihood of kidney stones in patients with flank pain, all used race to change their predictions of the likelihood or morbidities. However, they find that these algorithms were not sufficiently evidence based as “Some algorithm developers offer no explanation of why racial or ethnic differences might exist. Others offer rationales, but when these are traced to their origins, they lead to outdated, suspect racial science or to biased data”. Using race can then discourage racial minorities from receiving the proper treatment based on their scores, exacerbating already existing problems of unequal health outcomes.
Conclusion
So it is clear that anyone who intends to use race for diagnosis could harm racial minority groups. Race inherently is a complex social and economic phenomenon and cannot be said to be a clear biological variable. Hence anyone intending to use or create algorithms will run the risk of creating dangerous biases in treatment; ones that could worsen the existing disparities in care for vulnerable populations.
3. Values Statement
The potential users of this project are scholars and researchers who remain adamant in exploring the classification of race through the intersection of other socially constructed identities (gender, ethnicity, sexuality, etc.). There have been numerous literatures potentially identifying race as a proxy for categorizing and describing certain social, cultural, and biological characteristics of individuals or groups; it has also become pervasive in its history and role in the medical field. Those who are harmed and still are affected by this project would be the hidden bodies — the group of individuals historically marginalized in society — and whose very identities are in a constant battle of validity. In pursuit of this project, we acknowledge that the technology and results could further harm and perpetuate the racist ideologies that currently exists in validating the physiological differences across racial groups.
What is your personal reason for working on this problem?
Jay-U: My personal motivation for working on this project was my interest in Gichoya et al. (2022)’s paper. I thought it was very suprising that they were able to identify race from chest X-rays when I think that there should be nothing identifying about the images. I think that ethically it is problematic, so I wanted to explore their methods and verify if it was reproducible, as well as reading more about race and its use in medicine.
Kent: My personal reason for working on this project was to engage in an ethical conversation about the implications of classifying race through AI. Jay-U provided the initial literature to this project, and it motivated me to exercise bias auditing if any of the algorithms proved to be flawed.
4. Materials and Methods
Our Data
We used the ChexPert dataset collected by Irvin et al. (2019). The dataset contains images collected between between October 2002 and July 2017, where the dataset was eventually finalized after analyzing all images from Stanford Hospital. This dataset contains 224,316 frontal and lateral chest radiographs of 65,240 patients. Each radiograph is labeled with information such as age, gender, race, ethnicity and medical conditions, but we are primarily concerned with race and gender. A full structured datasheet of the ChexPert dataset has been explained by Garbin et al. (2021).
One limitation in the dataset includes a limited variety of x-ray devices to capture the images as the dataset is only coming from one institution — Stanford Hospital. Thus, models trained on this dataset may perform worse when compared to other institutions. Varied patients’ ages and sex may affect the representation of gender and age in the dataset.
White patients occupy the vast majority of this dataset, as shown by the following figure, and we are concerned that this may lead to a racial bias in the model’s classification algorithm.
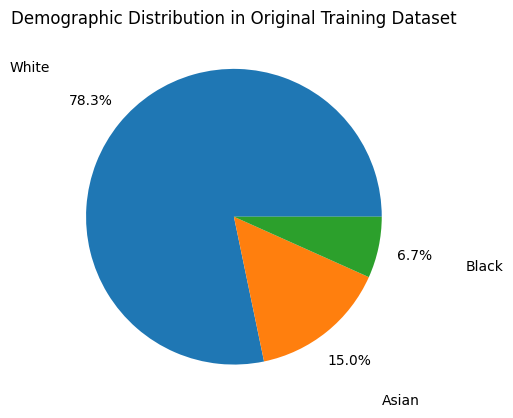
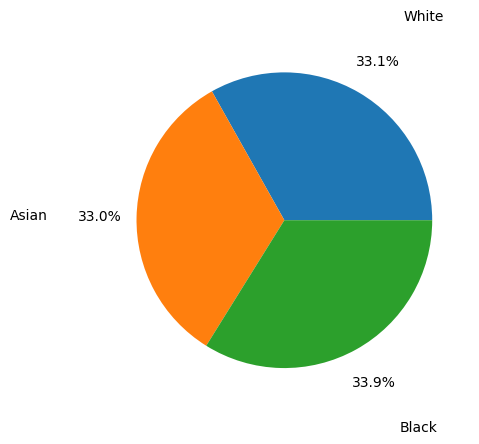
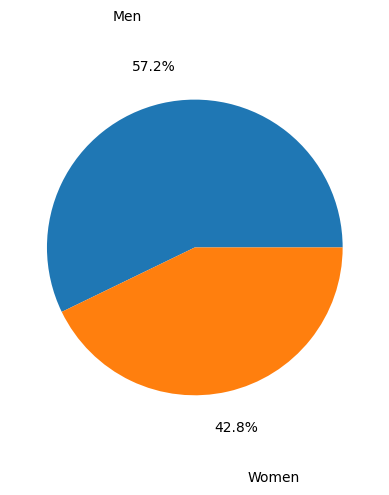
To account for this imbalance, we trained our model on a racially balanced subset of the ChexPert dataset. Even though there are more male than female patients in this training set, we would later learn that the model does not exhibit gender bias.
Our Method
We trained our model using 10,000 frontal chest X-rays, such as the one in the following figure, and the feature used as target is race. We only used 10,000 images due to the lack of computing power. This subset is equally divided among Asian, Black and White patients, and excludes other races to keep the algorithm simple.
As for our models, we used ResNet and EfficientNet because they are popular deep learning architectures for image classification. Specifically, we used pretrained EfficientNetB0 and ResNet18 models. We also implemented some ResNet18 models on our own but achieved a lower accuracy. To gauge what the ResNet18 model is “looking” at, we extracted the filters from the first convolutional layer to visualize the feature maps across three convolutional layers: layer 0, layer 8, and the last layer 16.
For the training data, we accessed the .csv file containing demographic details about the patients, extracted the path to each radiograph, and label each image with its owner’s race. The images are turned into tensors, and then loaded to be trained using the Adam optimizer. Because of the large size of the data, we did all training and testing on Google Colab.
To optimize a model, we would train it on 10,000 images in a loop using different learning rates for the Adam optimizer and \(\gamma\) values for the exponential scheduler. In the same loop, we would then test the model on 2,500 images to find the optimal parameters. Cross entropy loss was used for all models.
As mentioned before, there may be a gender bias in our model because there are more male than female patients in our training dataset. We inspected this by splitting our test set into male and female counterparts and testing the model on each subset. Gender bias is then examined by looking at the score and confusion matrix for each gendered subset.
5. Results
Loss and Accuracy History
We achieved a fairly efficient model that can predict with up to 80% accuracy whether a person is Asian, Black or White. Pretrained ResNet and EfficientNet models obtained similar accuracies and losses, so we will display only EfficientNet results. As we can see in the following figures, the training score and loss gradually improved while the validation score and loss plateau after a few epochs. This means that there was some overfitting. We tried to optimize the model by altering the scheduler type, varying the Adam learning rate from 0.001 to 0.01, but the overfitting did not go away. The score, however, remained consistently at around 75% throughout these changes.
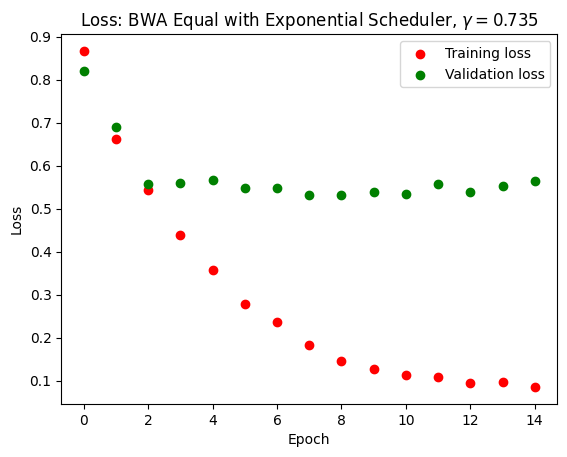
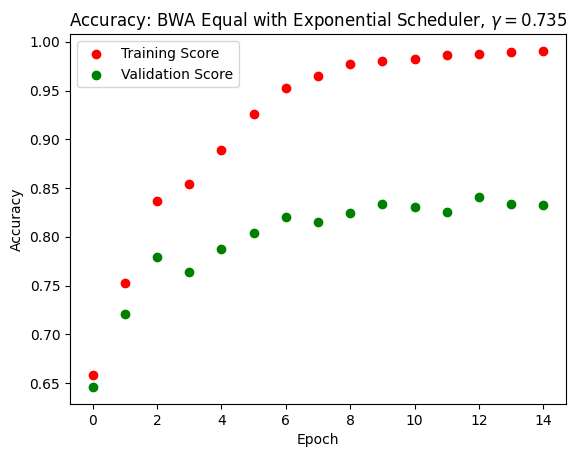
It is important to note that we did our training and testing on racially balanced datasets. Before optimization, we could only achieve good accuracy if we tested the model on a racially balanced test dataset. If we tested the model on a predominantly white dataset, the model tended to guess everyone to be white. After optimizing our model with the Adam optimizer learning rate at 0.001 and an exponential scheduler with \(\gamma = 0.735\), we achieved good accuracy on the imbalanced set without the model guessing everybody to be white.
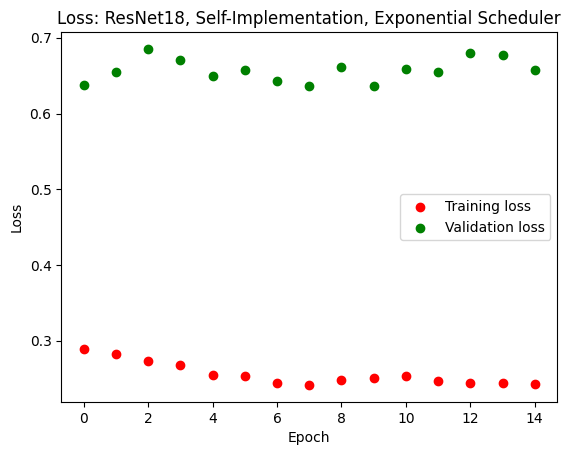
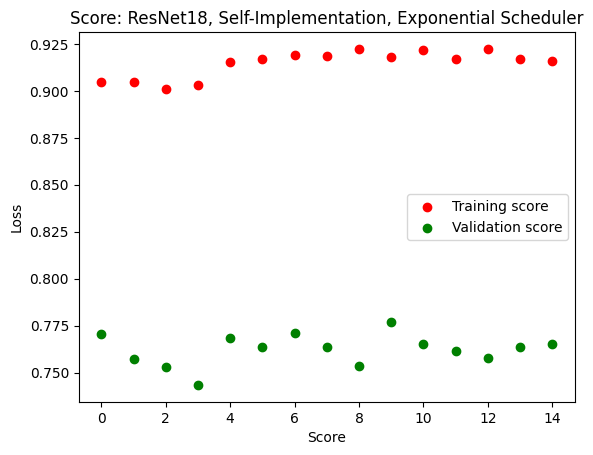
We also did our own implementation of ResNet18, and obtained comparable results. The issue of overfitting remained, and our model achieved a score of up to 68% when tested on unseen data. Because the pretrained EfficientNet model returned better results, we would explore gender bias on this model.
Confusion Matrix
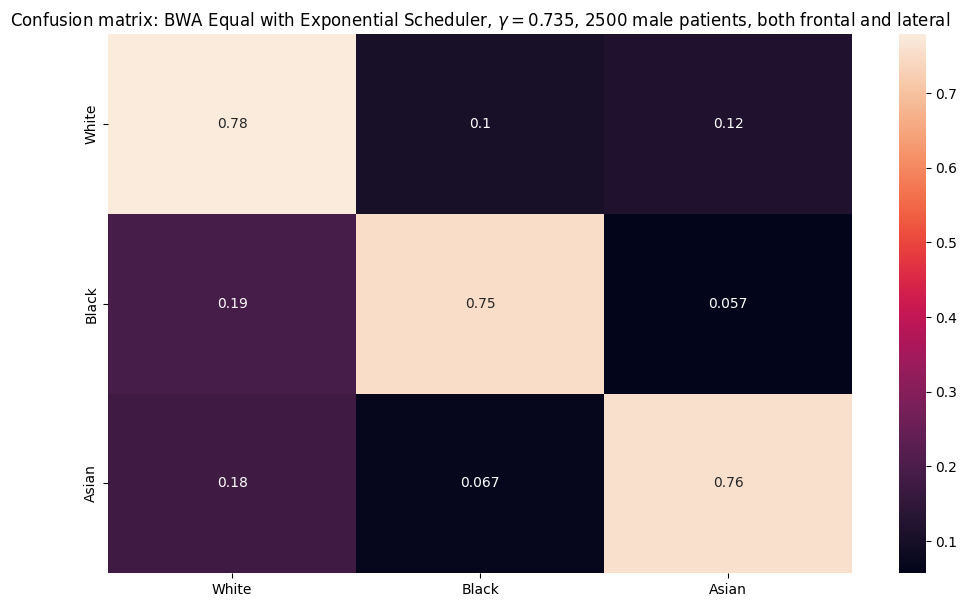
Shown below are the confusion matrices for the EfficientNet model with \(\gamma = 0.735\) over a subset of 2500 male and female patients for both frontal and lateral images. The horizontal axis represents the predicted classes (White, Black, Asian), and the vertical axis represents the true labels.
| Confusion matrix for male patients | Confusion matrix for female patients |
|---|---|
 |
 |
From the confusion matrices above, we notice that for male patients, the model classified White the best class, with 78% of the predictions to be true. Whereas, for the female patients, the model classified Asian the best class, with 79% of the predictions to be true. However, across all classes (White, Black, Asian), the percentage of true-positives are relatively the same and can be interpreted to be equivalent.
However, for both sexes, the Asian and Black classes tends to be classified as of the White class at a significant rate compared to the Black class.
For male patients, 19% of the Black class and 18% of the Asian class were predicted to belong to the White class. For female patients, 17% of the Black class and 15% of the Asian class were predicted to belong to the White class. These rates share similar performace to the misclassification of White patients as predicted Asian — as 12% of the male White class and 16% of the female White class were predicted as Asian. In contrast, the model has a significantly low percentage of classifying the Asian and White class as part of the Black class.
Thus, although we have trained on an equal subset of each class (White, Black, Asian), the confusion matrix suggests that there may be representational bias with how a certain class such as the White class will be more likely to be predicted than the Black and Asian class. Thus, though the model does classify each race at a relatively moderate accuracy (up to 80% accuracy), it may also be at the cost of producing inaccurate classifications to a patient’s true race — which is highly favored for those belonging in the White class. This can result in heavy implications if an algorithm like this were to be commercialized and probes the validity of similar algorithms that yield a “high” accuracy rates for the true races.
Visualized Feature Map
Using our self-implemented ResNet18 model, we demonstrate below the first convolutional layer’s filters, and the feature maps of three convolutional layers — layer 0, layer 8, and layer 16 (the last layer).
The patient used for this demonstration is a White, non-hispanic Female. Shown below is the patient’s frontal-view image used for this experiment.
| Frontal-view image of patient |
|---|
 |
And here is the first convolutional layer’s filter:
| First convolutional layer filter of the self-implemented ResNet-18 neural network model |
|---|
 |
Then, we passed the filter through each of the convolutional layers of the model. For simplicity, we only showed three of the total layers. It is interesting to see that there is varied noise as to what the model “looks” at, highlighted by the whiter patches of the image — which also corresponds to which part of the image is “activated”!
| Feature maps from the first convolutional layer (layer 0) of self-implemented ResNet18 model |
|---|
 |
| Feature maps from the ninth convolutional layer (layer 8) of self-implemented ResNet18 model |
|---|
 |
| Feature maps from the last convolutional layer (layer 16) of self-implemented ResNet18 model |
|---|
 |
After displaying the three layers, we observed that the last layer is highly disoriented, and the regular human eye can no longer distinguish the original image (the patient’s frontal-view). This last layer serves high importance as it is used to deduce what the model is actually classifying based off “features” it has learned. Additionally, we also observe that the model focused on different aspects of the image as the filters used to create the feature map vary.
6. Conclusion
The models that our project produced can classify race up to 80% accuracy based on chest X-rays. Given the confines on our time and computing power, this is comparable to models attained by Adleberg et al. (2022) and Gichoya et al. (2022). Our initial goal for the project was to see if the models are actually feasible, and we indeed achieved this goal.
We also investigated the ethical issues that these models could pose. We speculate that if the results of this project were used in bad faith, existing racial inequalities would be reinforced and worsened. Physiological differences between the races include not only visible features such as skin tone, but also unobservable, subcutaneous features such as bones. This has also been observed by Maglo, Mersha, and Martin (2016). They learned that this phenomenon results from racism itself, because prolonged exposure to effects of racism such as toxic stress can lead to observable physiological changes.
Another ethical issue that our models can pose is improved surveillance tactics. We learned that during World War II, people of certain ethnicities were incarcerated in various countries, and there were protocols that officials followed to check if an incarceree actually belonged in the condemned ethnic group. We also learned that there were those who actually evaded incarceration by assuming a different identity. With the introduction of a absolutely accurate racial classification model, nobody is safe, because there is no way to lie your way out of persecuation.
But of course, this is a stretch. The fact that our deep learning models can learn race is deeply concerning, because it means that race-based medicine can be administered by medical machines that are supposedly unbiased and reliable. The only way to overcome this is for the medical industry itself to stop using race as a vector in decision making.
Right now, our model is still in its infancy, and we do not know for sure what the model is looking at to make its decision. If we had more time and Google Colab premium, the first thing we would do is loop over all parameters of the Adam optimizer and the exponential scheduler to optimize our model and overcome overfitting. Once we achieved almost 100% accuracy, we would like to know whether the model was looking at physiological differences between patients to make its decision, or it was looking at something else. To achieve this, we would need more data from different sources and more Google Colab premiums.
7. Group Contributions Statement
Trong: I downloaded the ChexPert dataset to a shared drive to make the pathways in our Google Colab consistent; visualized racial and gender imbalances in the training data; trained ResNet18 models with different schedulers; visualized training and validation losses for each model; investigated gender bias for the pretrained EfficientNetB0 model. I tried to implement the code from here but it didn’t work. I also wrote the project presentation script, the blogpost, and finalized the ethics research.
Jay-U: I found the paper by Gichoya et. al on classifying race using Chest X-rays. I found the CheXpert dataset and created the subsets. I created the dataset function for the dataloader (including the transforms). I identified the algorithms to use and experimented with them, using the ResNet and EfficientNet algorithms. I also did a self-implementation on the ResNet18/ResNet34 algorithms and trained them. I implemented the training and testing functions, the optimization loop, and added the learning rate scheduler. I also created a way to save and load models, having trained the pretrained ResNet18 and EfficientNet algorithms with the exponential and plateu schedulers.
I also worked on the research, finding and doing the writeups for the introduction (the results similar to the work we’re doing). I also found the papers around race-based medicine and finished my write up. I made edits to the project presentation, and all sections of the blogpost.
Kent: I aided in exploratory data visualizations for the CheXpert dataset. I also implemented code to visualize the activation maps for the self-implemented ResNet18 model.
I helped format the project presentation and aided in editing a portion of the sections. I supported in writing the Values Statement, Methods (added datasheet) and Results (interpreting the confusion matrix + auditing for bias) sections, alongside creating the bibliography.
8. Personal Reflection
From the process of researching, implementing, and communicating about the project, I learned how much less coding and less technicality needed to even start the process of understanding the depths and motivations behind a ML-based project. Since our project laid heavy ethical implication, as a group, we really had to dig down deeply why this project would be beneficial, if applicable, and the stakeholders present in our project. A majority of the project’s foundation was grounded through previous literatures detailing how race is some factor found by scholars’ neural network models and AI. Thus, the implementation part of this project was focused on reproducing literatures’ architectures and algorithms to see if race can truly be classified at a higher rate — and at what cost. From a communication perspective, I think a major lesson I can take away into future courses/life would be that understanding is a shared skill. Since we were working in a Git workflow and through Google Colab, as well, we would often work asynchronously from one another. As a result, it was easy to get caught up with your own work and not have the chance to understand other members’ code.
From my project contributions, I feel that I did not meet my goals that I set for myself at the beginning of the semester. More specifically, I had wanted to be more engaged with the implementation of neural network models, but I was only able to contribute to data visualizations and interpretations of the models. Due to my physical absence to the major lectures dealing with image classification and neural networks, I felt that I was always catching up with what was present in my group’s codebase. In the future, I wish to be more active and attentive to the committed code and communicating with my team about what is potentially confusing. There could also be a group agreement in the beginning about the style of code we would envision ourselves working towards — as there were limited documentation to the code, it felt heavy to my eyes reading through our codebase.
I’ll definitely carry the experience and burden of how to be ethically involved with the algorithms that shape the world around us. Dr. Timnit Gebru’s virtual talk and this course has opened my eyes about how dominant and pervasive AI is. My opinion stands that biases will never cease to exist, but what we can do is to restrict and put a spotlight to the biases that we ourselves emit as well as the data/algorithms we comply to as “truth”. Truth to the corporate world is masked by their greed, and I think that as a future student/engineer with plans to work in the industry, I have to be conscious of the work that I do if it aligns with my values.